

9 Questions to Ask Before Deploying a High-Availability Cloud VPS
Developers

Zoran Gacovski · Nov 25, 2024 · 8 minute read
Picture this: Your online jewelry store crashes during Black Friday, your Forex trading platform goes dark during peak hours, or worse – your entire infrastructure fails when your customers need it most. These aren’t just hypothetical disasters; they’re the entirely possible disasters that keep system administrators awake at night.
When five minutes of downtime can cost thousands in lost revenue and customer trust, high-availability cloud VPS is the answer to the question: “How do we keep our systems running, no matter what?” Unlike traditional single-server setups that create a single point of failure, high-availability architectures in the cloud are your safety net, ensuring your services stay online even when individual components experience a hiccup.
This guide covers key questions to build a robust high-availability strategy, and will familiarize you with topics such as how to set availability requirements, design resilient architecture, implementing continuous deployment, and leverage the full range of your IaaS capabilities.
What Does High Availability of Cloud VPS Mean?
IT infrastructure with high availability continues running despite component failures. This is essential for businesses where downtime directly impacts the bottom line. This is crucial for every business that cannot tolerate outages, as any downtime can lead to harm or financial loss.
A highly available system guarantees specific uptime levels, measured in percentages. For example, 99.9% reliability limits annual downtime to only 8 hours. Five nines is the name of a benchmark you’ll hear a lot. It refers to a system that is up 99.999% of the time.
To achieve a highly available VPS setup, the following 3 elements are essential:
- Redundancy refers to having a backup component for crucial system operations in case of failure.
- Monitoring involves collecting data from a system and recognizing component failures or stops functioning.
- Failover is a technique that automatically switches from an active to a redundant component upon failure.
Why is High Availability Important?
High availability (HA) guarantees that users, clients, and companies can always access and use vital systems, applications, and services. HA is significant for the following reasons:
- Business continuity: HA ensures that companies continue to function normally, even in case of a malfunction. For businesses that rely significantly on technology, this is crucial.
- Increased productivity: HA ensures workers get the resources they need to complete their tasks, avoiding obstacles and enabling them to work as efficiently as possible.
- Revenue protection: For e-commerce, finance, and other online industries, downtime can lead to a considerable loss of revenue. By guaranteeing system availability, HA reduces the possibility of lost income and sales.
- Customer satisfaction: Customers anticipate having 24/7 access to services and apps. By ensuring that clients can get what they need when they need it, HA raises client loyalty and satisfaction levels.
- Brand reputation: A company’s reputation and customer trust can be weakened by frequent outages or downtime. HA maintains a positive brand image by guaranteeing that services are constantly available.
9 Questions to Ask to Achieve High VPS Cloud Availability
How can you guarantee seamless operation of your cloud VPS infrastructure? By addressing these key questions, you’ll be well-equipped to build a highly available and resilient system.
1. What is the current availability of your existing infrastructure?
To assess your current uptime and performance, as well as your existing points of failure, the main availability metrics will usually include:
- Mean time to recovery (MTTR)
- Mean time between failures (MTBR)
- Percentage of uptime
- Recovery time objective (RTO)
You can use a combination of these to define your desired service level agreement (SLA) for every application scenario.
2. Which factors affect the availability of your VPS?
Virtual Private Server (VPS) availability hinges on several key technical factors. Hardware reliability, network infrastructure, data center design, and virtualization technology all play critical roles in determining your server’s uptime. Physical components like hard drives and network interfaces can fail unexpectedly, while network connectivity issues can disrupt service.
Your cloud provider’s infrastructure—including power systems, cooling mechanisms, and failover capabilities—directly impacts how quickly your VPS can recover from potential disruptions. The right combination of redundancy, strategic server placement, and robust virtualization platforms can ensure minimal downtime.

3. What is your disaster recovery plan?
Data backup and recovery are critical to maintaining business continuity. A robust recovery strategy automatically restores data from backup locations, creating a safety net for your critical systems.
By establishing redundancy and failover mechanisms, you ensure that your infrastructure can quickly recover from potential data loss or system failures. Leveraging backup data centers allows you to perform routine maintenance without interrupting your website or application’s operations, maximizing uptime and minimizing service disruptions.
4. How will you implement redundancy?
Adding redundancy to a cloud computing system can be achieved by allocating multiple resources to perform the same function, essentially designing multi-server architectures. A cluster contains servers (or nodes) which are its components. Many nodes with related functions make up the cluster, which consumers usually access and perceive as a single entity.
In the event of a failure, any node in the cluster may be able to switch to another node, using load balancing technology. So, your website remains available even if one server goes down.
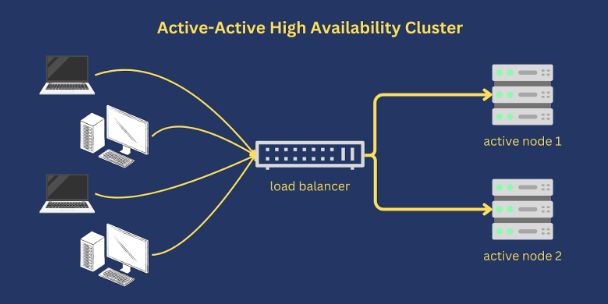
5. Why do you need a failover mechanism?
The process of switching from a downed server to one that is operating properly is known as failover. If your failover procedures are adequate, users won’t be aware that you’re rerouting them to a different node.
If monitoring indicates that the active component is failing, the failover mechanism can immediately transition from the active component to a redundant component.
6. Why do you need data replication?
In a typical architecture, you probably have a set of files and one database hosted on a single server. In a high-availability infrastructure, you must ensure the files and the database are available on all cluster nodes. The amount of traffic that today’s websites typically perform, makes this already difficult process even more difficult.
Today, a single button click could result in a new data entry that needs to be saved for later use. This happens hundreds or thousands of times every second on a busy website. In a high-availability environment, it can be difficult to ensure millions of people can see changes simultaneously.
7. Why is end-to-end testing important?
You should test the system under actual failure scenarios to guarantee reliability. Use fault injection testing to test many failure situations (including a combination of failures) and measure the recovery time. Make sure to test both failback and failover. You can perform additional tests to boost your confidence:
- Find failures while a system is under load, test it realistically until it breaks, and see how the failure mechanisms act.
- Perform scheduled or spontaneous disaster recovery exercises in which your team must follow your disaster recovery plan if systems fail.
- Test monitoring systems: Regularly verify the accuracy of data from monitoring systems to ensure you can identify failures early.
8. Which security measures can protect your high availability?
Deploying new application code, making configuration changes, and provisioning virtual machines or other services can all lead to failure. An automated, reliable deployment procedure can reduce the possibility of mistakes and will facilitate recovery.
Plan your release procedure to provide upgrades with the least amount of service interruption possible; aim for rolling updates that don’t need major component outages. Create a rollback procedure that will enable you to automatically restore systems to a prior functional state. To enable the spin-up of a full environment that represents your “last known good” configuration, you should automate deployments.
9. How will you monitor your system’s health?
Timely failure detection is essential to high availability. Apply check functions and health probes to obtain up-to-date information on service availability. Check functions should always be run from outside of an application. By monitoring application health indicators and alert operators when a system hits a dangerous threshold value, you can establish an early warning system.
- Utilize robust logging and auditing features,
- Separate application logs from audit logs,
- Use semantic and asynchronous logging,
- Measure remote call metrics like latency, throughput, and error percentage.
Best Practices to Achieve High Availability
Achieving true high availability requires more than just selecting the best cloud provider or implementing backup systems. It demands a comprehensive approach that encompasses architecture design, monitoring strategies, automation, and disaster recovery planning.These battle-tested best practices will help you build and maintain cloud infrastructure capable of weathering everything from minor hiccups to major outages, ensuring your services remain available when your users need them most.
To achieve high availability of your VPS setup, here are some best practices we’ve put together to keep your operations running at peak performance.
- Prioritize redundancy by automating failover to reduce downtime and utilizing backup instances for essential components.
- To guard against localized failures, use load balancing to split resources and traffic among several sites.
- Utilize automatic scaling to manage variations in demand, monitor the health of the system, and periodically backup and replicate data.
- To resolve problems quickly, apply failover procedures and provide self-healing features.
Conclusion
Downtime is no longer an option. Businesses rely on cloud servers to operate seamlessly, 24/7. To achieve this level of reliability, it’s crucial to implement robust high availability strategies. As you implement these practices in your own environment, focus on incremental improvements. Remember that even the most robust systems require regular review and refinement to maintain their effectiveness. By staying committed to these principles and remaining adaptable in your approach, you can build cloud infrastructure that not only meets today’s availability requirements but is also prepared for tomorrow’s challenges.
Dr. Zoran Gacovski is a full professor at Mother Teresa University in Skopje, Macedonia. His areas of research are information systems, intelligent control, machine learning, and human-computer interaction.
Prof. Gacovski served as a Fulbright postdoctoral fellow in 2002 at Rutgers University.
He has published more than 300 highly technical IT articles, as well as books (available on Amazon). His portfolio can be retrieved on Google Scholar, ResearchGate, and Academia.edu.
Learn more